LoRA Explained: A Smarter Way to Fine-Tune Custom AI Models
Low-Rank Adaptation (LoRA) is a breakthrough method for fine-tuning large language models (LLMs) without the heavy cost of retraining the entire network. Instead of updating every parameter in a massive AI model, LoRA introduces a small number of trainable weights - allowing you to efficiently adapt a pretrained model to your specific data and use case. The result is a highly customized AI model that performs like a heavyweight, but trains faster and runs on lighter infrastructure.
For businesses, this means you can build AI solutions tailored to your domain. Whether your business is legal, medical, logistics, manufacturing, construction, or anything else - you can use LoRA to infuse your domain-specific knowledge into a pre-trained AI model. With LoRA training, you keep costs low and are staying in control of your data.
LoRA fine-tuning supports compliance and privacy by allowing on-premise or private-cloud training, and makes AI adaptation accessible even without a fleet of GPUs.
The CFO's AI Dilemma: Balancing Innovation And Cost
Large language models (LLMs) have propelled conversational AI into boardroom strategy sessions. However their total cost of ownership raises serious concerns for CFOs. Between high-end GPU clusters, frequent retraining cycles, and complex data privacy reviews, scaling AI models can quickly become unsustainable.
Low-Rank Adaptation (LoRA) offers a smarter path forward. As a parameter-efficient AI fine-tuning technique, LoRA enables you to customize powerful pre-trained AI models for your domain with dramatically lower compute and storage requirements. According to Gartner, parameter-efficient fine-tuning is expected to reduce AI customization costs by up to 70% by 2026. In this post, you'll learn what LoRA is, how it works, and how your organization can see real ROI in under six months.
Why Traditional Fine-Tuning Of AI Models Falls Short
While fine-tuning a foundational AI model might sound like the fastest way to customize AI solution for your business, the reality is more complex - and expensive. Traditional full-model fine-tuning creates hidden costs, compliance risks, and environmental concerns that most teams can't afford to ignore.
- Sky-High Compute and Storage Costs Fine-tuning a full AI model can consume hundreds of GPU hours and dramatically inflate storage needs. Even a relatively small 13B-parameter model requires over 20 GB of storage per industry use case.
- Compliance and IP Leakage Risks Updating all model weights blends your proprietary data with the original AI model checkpoint. This raises intellectual property concerns and makes it harder to maintain clean audit trails.
- Environmental Impact MIT's Green AI study found that retraining GPT-class models can emit as much CO2 as five cars over their entire lifetimes. That's a steep carbon footprint for customizing a chatbot.
LoRA 101: How Low-Rank Adaptation Works
- Freeze the base AI model Keep original weights untouched for stability and safety.
- Add lightweight adapters Insert small trainable rank-r matrices into attention layers.
- Train efficiently= Only the new matrices are updated - reducing trainable parameters by over 90%.
- Deploy flexibly Save LoRA adapters separately (~30�MB) and merge with the base model at inference time.
This modular approach keeps the core model intact, simplifying version control and rollback. It also allows you to fine-tune for multiple domains or clients without duplicating large AI models - making AI customization scalable and cost-effective.
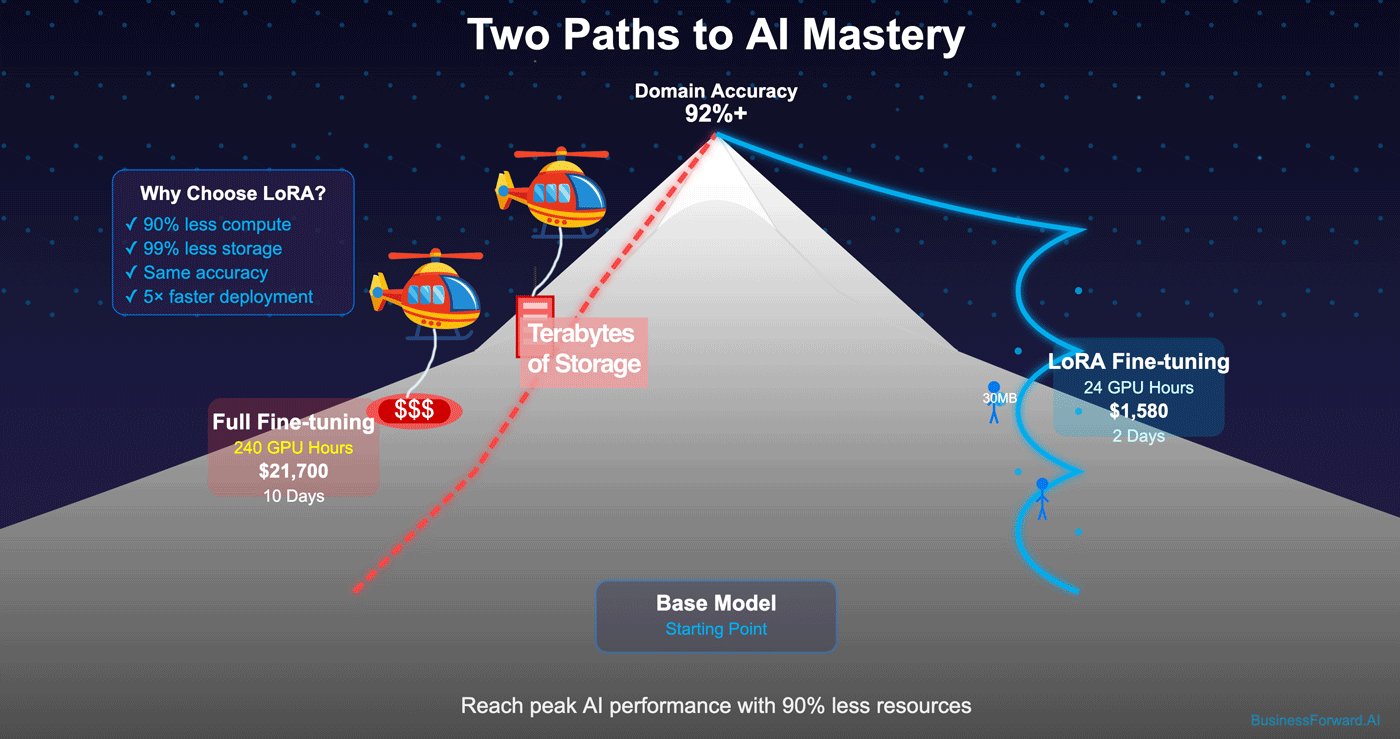
LoRA vs Full AI Model Fine-Tuning: Business Impact Metrics
| Metric | Full Fine-Tuning | LoRA Fine-Tuning | Delta |
|---|---|---|---|
| GPU hours (13 B model) | 240+ | 24 | -90 % |
| Storage per domain | 20 GB | 30 MB | -99 % |
| Compliance audit time | 4 weeks | 1 week | -75 % |
| Time to fine-tune | 10 days | 2 days | -80 % |
Anonymized Case For LoRA Fine-Tuning
A fintech firm produced a domain-specific AI chatbot that passed 92 % intent accuracy in five languages. LoRA adapters cost $1 580 vs $21 700 for full fine-tuning.Step-by-Step Framework for Fine-Tuning AI Models with LoRA
Fine-tuning large language models with Low-Rank Adaptation (LoRA) can dramatically reduce cost and training time - if you follow the right process. Below is a practical framework for applying LoRA to your custom AI use case.
1. Define the Target Use Case
Start by identifying your primary goal: is it text classification, document summarization, or multi-turn dialogue?
The task type and accuracy requirements will help determine the optimal adapter rank r.
2. Curate High-Quality Training Data
When it comes to AI model fine-tuning, quality beats quantity. Gather 1,000�3,000 clean, well-labeled examples. Use data augmentation sparingly - introducing too much synthetic data can degrade model performance.
3. Select a Base AI Model and Adapter Rank
Choose an open-weight foundation model such as Llama 3-8B or similar.
Start with rank=8; increase only if evaluation metrics plateau. Keep storage and latency trade-offs in mind.
4. Train Your LoRA Adapters
Use libraries like peft or LoRA-Trainer for fast, efficient training.
Enable mixed-precision (bfloat16) to cut GPU memory usage in half.
A single A100 GPU can complete training overnight for most business cases.
5. Evaluate Final AI Model Safety and Performance
Build a red-teaming prompt set to test for edge cases, such as PII leakage, policy violations, or brand voice drift. Evaluate metrics such as perplexity, hallucination rate, and instruction adherence.
6. Deploy and Monitor in Production
Attach LoRA adapters dynamically at load time, detach to roll back instantly. Track production metrics - latency, token-level accuracy, completion quality - using observability tools like Grafana or Prometheus.
LoRA Implementation Timeline and Resource Plan
| Phase | Duration | Key Roles | Deliverables |
|---|---|---|---|
| Use Case Definition | 1 week | Product, ML Lead | Success KPIs, rank estimate |
| Data Prep | 2 weeks | Data Eng, SME | Curated dataset |
| Adapter Training | 3 days | ML Eng | LoRA checkpoint |
| Evaluation | 1 week | QA, Ethics Board | Metrics & safety report |
| Deployment | 1 week | DevOps, SecOps | Prod rollout, dashboards |
LoRA Fine_Tuning ROI Calculator
Quick formula for CFOs:
ROI = (Baseline cost - Post-LoRA cost - Implementation cost) / Implementation cost
Plugging numbers from our fintech case yields ROI = (540 K - 140 K - 60 K) / 60 K = 5.6 � within Year 1.
Common LoRA Fine-Tuning Pitfalls and How to Avoid Them
- Rank inflation: Higher r not equals better. Start small; scale with evidence.
- Data drift: Re-train adapters quarterly or when accuracy drops >2 pts.
- Inference mismatch: Ensure production loads adapters in the same dtype (same data precision) as training.
Strategic Considerations and Future Trends
- Composable Adapters: Stack emotion, domain, and persona adapters at inference.
- Edge Deployment: 8-bit quantized base + LoRA runs on iPhone-class hardware. You can use LoRA trained models in the mobile apps for implementing voice interaction in the the business apps, such as inventory management or mobile forms.
- Regulatory Ready: Separate adapters simplify "right to be forgotten" compliance.
